Docling Parse:专注于从程序化 PDF 中高效提取文本、路径及位图资源的轻量级工具包。
• 支持字符、单词及行级别文本坐标输出,精准定位文本内容,方便深度版面分析与可视化
• 同时提取路径和位图图像,满足复杂文档结构解析需求
• 内置可交互式可视化脚本,便于快速验证与展示解析效果
• 性能显著提升,最新版本解析速度较初版快 5-10 倍,适合大规模文档处理
• Python 包即装即用,支持命令行和编程接口,灵活集成到多种工作流
• 完全开源,MIT 许可,社区活跃,持续更新与优化,便于二次开发和创新
• 适合科研、文档数字化、信息抽取等多场景应用,助力文档数据智能化转型
基于程序化 PDF 结构,精细提取多层级文本单元与图形元素,融合性能优化与可视化,推动 PDF 内容的结构化理解与应用扩展。
#资源参考 #工具 #AI #PDF提取文本图像
• 支持字符、单词及行级别文本坐标输出,精准定位文本内容,方便深度版面分析与可视化
• 同时提取路径和位图图像,满足复杂文档结构解析需求
• 内置可交互式可视化脚本,便于快速验证与展示解析效果
• 性能显著提升,最新版本解析速度较初版快 5-10 倍,适合大规模文档处理
• Python 包即装即用,支持命令行和编程接口,灵活集成到多种工作流
• 完全开源,MIT 许可,社区活跃,持续更新与优化,便于二次开发和创新
• 适合科研、文档数字化、信息抽取等多场景应用,助力文档数据智能化转型
基于程序化 PDF 结构,精细提取多层级文本单元与图形元素,融合性能优化与可视化,推动 PDF 内容的结构化理解与应用扩展。
#资源参考 #工具 #AI #PDF提取文本图像
NVIDIA AI Blueprint:大规模视频搜索与摘要的行业级解决方案
• 支持海量实时及存档视频的智能摄取与结构化分析,助力快速决策与运营优化
• 结合视觉语言模型(Cosmos Nemotron VLM)、大型语言模型(Llama Nemotron LLM)及NVIDIA NIM微服务,实现精准视频摘要和交互式问答
• 采用Context-Aware RAG模块,融合向量库与图数据库,增强多跳推理、时序理解及异常检测能力
• 灵活部署:支持单GPU、局部多GPU及完全远程架构,满足从开发到生产的多种场景需求
• 面向视频分析师与AI开发者,提供一键部署、丰富配置及高度可定制化的流水线和微服务
• 完善文档覆盖API授权、硬件需求、快速上手指南及安全漏洞说明,保障稳定可靠运行
• 典型应用涵盖智能空间监控、仓储自动化及标准作业流程验证,赋能行业数字化转型
视频智能分析已进入多模态融合与上下文增强的新阶段,NVIDIA蓝图提供了系统化路径,降低复杂度,提升效率,释放视频数据的最大价值。
• 支持海量实时及存档视频的智能摄取与结构化分析,助力快速决策与运营优化
• 结合视觉语言模型(Cosmos Nemotron VLM)、大型语言模型(Llama Nemotron LLM)及NVIDIA NIM微服务,实现精准视频摘要和交互式问答
• 采用Context-Aware RAG模块,融合向量库与图数据库,增强多跳推理、时序理解及异常检测能力
• 灵活部署:支持单GPU、局部多GPU及完全远程架构,满足从开发到生产的多种场景需求
• 面向视频分析师与AI开发者,提供一键部署、丰富配置及高度可定制化的流水线和微服务
• 完善文档覆盖API授权、硬件需求、快速上手指南及安全漏洞说明,保障稳定可靠运行
• 典型应用涵盖智能空间监控、仓储自动化及标准作业流程验证,赋能行业数字化转型
视频智能分析已进入多模态融合与上下文增强的新阶段,NVIDIA蓝图提供了系统化路径,降低复杂度,提升效率,释放视频数据的最大价值。
#开源 #抓包 #工具
🔗 ProxyPin - 开源免费抓包工具
您可以使用它来拦截、检查和重写 HTTP(S) 流量,支持手机扫码连接、域名过滤、搜索、请求重写等功能
支持Windows、Mac、Android、IOS、Linux 全平台系统
🔗 ProxyPin - 开源免费抓包工具
您可以使用它来拦截、检查和重写 HTTP(S) 流量,支持手机扫码连接、域名过滤、搜索、请求重写等功能
支持Windows、Mac、Android、IOS、Linux 全平台系统
#prompt #AI
🔗 Prompt Optimizer - 一个开源的提示词优化工具
输入提示词就可以开始优化,支持多个 AI 大模型,可直观查看、对比提示词优化
支持在线使用、Chrome 插件、Vercel部署、Docker部署
📑相关阅读
PromptPilot - 字节跳动推出的 AI 提示词优化工具
🔗 Prompt Optimizer - 一个开源的提示词优化工具
输入提示词就可以开始优化,支持多个 AI 大模型,可直观查看、对比提示词优化
支持在线使用、Chrome 插件、Vercel部署、Docker部署
📑相关阅读
PromptPilot - 字节跳动推出的 AI 提示词优化工具
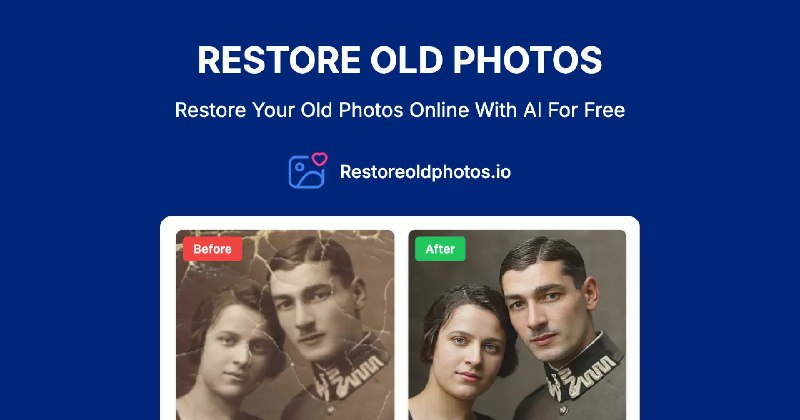
#自动化 #自媒体 #工具
🔁 自媒体运营助手 - 一个开源的浏览器自动化工具
⬇️ 下载页面
自媒体运营工具支持一键视频搬家、下载,一键发布视频到多平台,一键搬家到快手、YouTube、小红书、美拍、哔哩哔哩等平台
支持 Windows、macOS
🔁 自媒体运营助手 - 一个开源的浏览器自动化工具
⬇️ 下载页面
自媒体运营工具支持一键视频搬家、下载,一键发布视频到多平台,一键搬家到快手、YouTube、小红书、美拍、哔哩哔哩等平台
支持 Windows、macOS
#开源 #下载工具
🎓 knowledge-grab - 国家中小学智慧教育平台资源下载器
⬇️ 下载页面
功能是可以从国家中小学智慧教育平台下载特定教育资源,支持批量下载、分类下载。支持Windows、macOS、Linux
☀️ 适合教育工作者、家里有娃的家长
🎓 knowledge-grab - 国家中小学智慧教育平台资源下载器
⬇️ 下载页面
功能是可以从国家中小学智慧教育平台下载特定教育资源,支持批量下载、分类下载。支持Windows、macOS、Linux
☀️ 适合教育工作者、家里有娃的家长
Telegraphite 是一款功能强大的工具,用于从公开 Telegram 源中提取和保存帖子,具有多种功能。
它支持从多个频道提取帖子、以 JSON 格式保存数据、上传媒体文件和按关键字过滤。
该工具可在计划模式和连续模式下运行,并能删除重复的帖子。
可按关键字或内容类型(纯文本、纯媒体)筛选。
数据存储在结构化目录中,每个 posts.json 文件都包含帖子信息,如 ID、日期和内容。
🧬 https://github.com/hamodywe/telegram-scraper-TeleGraphite
#tools
它支持从多个频道提取帖子、以 JSON 格式保存数据、上传媒体文件和按关键字过滤。
该工具可在计划模式和连续模式下运行,并能删除重复的帖子。
可按关键字或内容类型(纯文本、纯媒体)筛选。
数据存储在结构化目录中,每个 posts.json 文件都包含帖子信息,如 ID、日期和内容。
🧬 https://github.com/hamodywe/telegram-scraper-TeleGraphite
#tools
高效上下文工程实用指南,助力 Gemini 2.5 和 ManusAI 优化性能与成本控制:
• 上下文顺序关键🧩:采用“追加式”上下文,将新信息追加到末尾,提升缓存命中率,降低4倍成本与延迟。
• 工具管理需稳定🔧:避免任务中途变更工具顺序或可用性,防止缓存失效和模型混乱。
• 外部记忆不可少💾:主动写入上下文和目标至外部存储,防止信息丢失。Manus 典型任务需调用约50次工具。
• 定期复述目标🎯:让模型周期性重申任务目标,保持关注重点,防止迷失方向。
• 错误信息要保留⚠️:上下文中保留错误提示,帮助模型从错误中学习,避免重复失误。
方法论核心在于稳定输入结构与闭环反馈,确保模型持续聚焦与高效执行,提升长期任务可靠性与成本效益。
• 上下文顺序关键🧩:采用“追加式”上下文,将新信息追加到末尾,提升缓存命中率,降低4倍成本与延迟。
• 工具管理需稳定🔧:避免任务中途变更工具顺序或可用性,防止缓存失效和模型混乱。
• 外部记忆不可少💾:主动写入上下文和目标至外部存储,防止信息丢失。Manus 典型任务需调用约50次工具。
• 定期复述目标🎯:让模型周期性重申任务目标,保持关注重点,防止迷失方向。
• 错误信息要保留⚠️:上下文中保留错误提示,帮助模型从错误中学习,避免重复失误。
方法论核心在于稳定输入结构与闭环反馈,确保模型持续聚焦与高效执行,提升长期任务可靠性与成本效益。

构建知识图谱的核心工具:LangChain LLM Graph Transformer
• 将非结构化文本高效转化为结构化知识图谱,实体与关系一目了然,支持复杂多跳推理和检索增强生成(RAG)应用。
• 双模式支持:默认工具模式利用LLM结构化输出或函数调用,精准提取节点、关系及属性;备选提示模式通过few-shot提示实现兼容无工具支持模型,确保广泛适用。
• 灵活定义图谱Schema,支持节点类别、关系类型及属性的细粒度设定,显著提升提取一致性与准确性,减少不同运行间的输出波动。
• 严格模式(strict_mode)自动过滤不符合Schema的冗余信息,保证图谱清晰规范,便于后续分析与应用。
• 兼容Neo4j图数据库,支持云端Neo4j Aura或本地部署,便捷导入图谱数据,且可附带源文档实现结构化与非结构化检索融合。
• 采用异步处理,多文档并行提取,大幅提升效率,适合大规模知识图谱构建。
• 目前属性抽取仅限工具模式,属性均以字符串形式存在,属性定义为全局统一,未来可期待更细化定制。
通过结构化图谱表达复杂实体关系,极大增强数据的可查询性与推理能力,突破传统文本检索瓶颈,推动知识驱动型智能应用迈向新高度。
• 将非结构化文本高效转化为结构化知识图谱,实体与关系一目了然,支持复杂多跳推理和检索增强生成(RAG)应用。
• 双模式支持:默认工具模式利用LLM结构化输出或函数调用,精准提取节点、关系及属性;备选提示模式通过few-shot提示实现兼容无工具支持模型,确保广泛适用。
• 灵活定义图谱Schema,支持节点类别、关系类型及属性的细粒度设定,显著提升提取一致性与准确性,减少不同运行间的输出波动。
• 严格模式(strict_mode)自动过滤不符合Schema的冗余信息,保证图谱清晰规范,便于后续分析与应用。
• 兼容Neo4j图数据库,支持云端Neo4j Aura或本地部署,便捷导入图谱数据,且可附带源文档实现结构化与非结构化检索融合。
• 采用异步处理,多文档并行提取,大幅提升效率,适合大规模知识图谱构建。
• 目前属性抽取仅限工具模式,属性均以字符串形式存在,属性定义为全局统一,未来可期待更细化定制。
通过结构化图谱表达复杂实体关系,极大增强数据的可查询性与推理能力,突破传统文本检索瓶颈,推动知识驱动型智能应用迈向新高度。

面向开发者和内容创作者的先进视频制作框架,专注于用代码驱动视频生成与编辑,提升工作流效率与创意自由度。🎥
• 基于 React,支持用熟悉的前端技术构建高质量视频组件,实现动态内容与交互式设计。
• 提供完整渲染管线,兼容浏览器和服务器端渲染,确保视频输出高效且稳定。
• 支持多种格式导出,灵活适配不同平台需求,覆盖社交媒体、广告及教育视频制作场景。
• 内置时间轴和动画控制,便于精细调整视频节奏和视觉效果,提升内容表现力。
• 强调代码驱动的创作流程,促进版本管理、团队协作及自动化生产,适合规模化视频项目。
• 开源生态活跃,拥有丰富插件与社区支持,持续优化功能与性能。
Remotion通过代码与视频的结合,打破传统编辑限制,推动视频制作进入高度模块化与自动化时代。适合追求效率与创新的专业团队长期参考与应用。
Remotion | #框架
• 基于 React,支持用熟悉的前端技术构建高质量视频组件,实现动态内容与交互式设计。
• 提供完整渲染管线,兼容浏览器和服务器端渲染,确保视频输出高效且稳定。
• 支持多种格式导出,灵活适配不同平台需求,覆盖社交媒体、广告及教育视频制作场景。
• 内置时间轴和动画控制,便于精细调整视频节奏和视觉效果,提升内容表现力。
• 强调代码驱动的创作流程,促进版本管理、团队协作及自动化生产,适合规模化视频项目。
• 开源生态活跃,拥有丰富插件与社区支持,持续优化功能与性能。
Remotion通过代码与视频的结合,打破传统编辑限制,推动视频制作进入高度模块化与自动化时代。适合追求效率与创新的专业团队长期参考与应用。
Remotion | #框架

n8n 开源自动化生态全景图,聚焦社区前100热门节点,构建高效工作流的必备资源库
• 2515+ 社区节点,涵盖通信、文档生成、浏览器自动化、数据处理、API 集成、AI 语音、文件处理等八大类,持续高速增长,平均每日新增14.5个节点。
• 通信与消息节点支持 WhatsApp、Zalo、Discord、ChatWoot 等主流渠道,月下载量最高节点突破190万,助力多渠道消息自动化。
• 文档与内容生成节点支持动态文档、二维码、Notion 转 Markdown、AI PDF 生成,提升内容创作效率。
• 浏览器自动化与网络爬虫节点集成 Puppeteer、Playwright、ScrapeNinja,简化网页数据抓取与自动操作。
• 数据处理节点覆盖文本处理、OCR、加密解密、数据验证等多样功能,保障数据质量与安全。
• API 与云服务节点涵盖 Asaas、Apify、Brave Search、Kommo、Binance、TikTok、Power BI 等主流平台,打通业务系统边界。
• AI、LLM 及语音节点紧跟前沿,支持 ElevenLabs 语音合成、Perplexity AI、AI 图像生成等,赋能智能化自动化。
• 文件与 PDF 节点强力支持图片转 PDF、视频编辑等多媒体处理,扩展工作流应用场景。
• 社区维护活跃,节奏快,数据实时更新,适合长期参考与二次开发,助力构建可持续的自动化体系。
n8n 生态通过开放社区节点的持续迭代,打造了一个灵活、可扩展的自动化底座,赋能开发者和企业实现端到端的数字化转型。
#资源参考 #AI #n8n
• 2515+ 社区节点,涵盖通信、文档生成、浏览器自动化、数据处理、API 集成、AI 语音、文件处理等八大类,持续高速增长,平均每日新增14.5个节点。
• 通信与消息节点支持 WhatsApp、Zalo、Discord、ChatWoot 等主流渠道,月下载量最高节点突破190万,助力多渠道消息自动化。
• 文档与内容生成节点支持动态文档、二维码、Notion 转 Markdown、AI PDF 生成,提升内容创作效率。
• 浏览器自动化与网络爬虫节点集成 Puppeteer、Playwright、ScrapeNinja,简化网页数据抓取与自动操作。
• 数据处理节点覆盖文本处理、OCR、加密解密、数据验证等多样功能,保障数据质量与安全。
• API 与云服务节点涵盖 Asaas、Apify、Brave Search、Kommo、Binance、TikTok、Power BI 等主流平台,打通业务系统边界。
• AI、LLM 及语音节点紧跟前沿,支持 ElevenLabs 语音合成、Perplexity AI、AI 图像生成等,赋能智能化自动化。
• 文件与 PDF 节点强力支持图片转 PDF、视频编辑等多媒体处理,扩展工作流应用场景。
• 社区维护活跃,节奏快,数据实时更新,适合长期参考与二次开发,助力构建可持续的自动化体系。
n8n 生态通过开放社区节点的持续迭代,打造了一个灵活、可扩展的自动化底座,赋能开发者和企业实现端到端的数字化转型。
#资源参考 #AI #n8n
专为开发者优化的 Claude Code 扩展框架,融合专用命令、智能角色与 MCP 服务器,助力高效开发流程。
• 16 条高频开发命令覆盖实现、构建、设计、分析、测试、文档等核心环节,提升任务执行效率🛠
• 多领域智能角色(架构师、前端、后端、安全等)自动匹配专家视角,精准应对复杂场景🎭
• MCP 服务器集成支持官方文档调用、UI 组件生成、浏览器自动化,扩展能力显著提升🔧
• 统一 CLI 安装器和多种安装方式,兼容 Python 3.8+,支持跨平台 uv / uvx 快速部署
• 任务管理与 Token 优化机制,保障长会话下的上下文连贯与资源节省
• v3 架构更简洁、性能更优,移除钩子系统以待 v4 重新设计,持续迭代中
SuperClaude 通过模块化设计与智能路由,将 AI 助手从泛用工具转变为开发者的多面能手,提升协同效率与专业深度。
长期价值:架构调整体现对稳定性与可扩展性的深刻理解,代码与文档开放,适合持续贡献与社区共建。
SuperClaude v3 | #框架
• 16 条高频开发命令覆盖实现、构建、设计、分析、测试、文档等核心环节,提升任务执行效率🛠
• 多领域智能角色(架构师、前端、后端、安全等)自动匹配专家视角,精准应对复杂场景🎭
• MCP 服务器集成支持官方文档调用、UI 组件生成、浏览器自动化,扩展能力显著提升🔧
• 统一 CLI 安装器和多种安装方式,兼容 Python 3.8+,支持跨平台 uv / uvx 快速部署
• 任务管理与 Token 优化机制,保障长会话下的上下文连贯与资源节省
• v3 架构更简洁、性能更优,移除钩子系统以待 v4 重新设计,持续迭代中
SuperClaude 通过模块化设计与智能路由,将 AI 助手从泛用工具转变为开发者的多面能手,提升协同效率与专业深度。
长期价值:架构调整体现对稳定性与可扩展性的深刻理解,代码与文档开放,适合持续贡献与社区共建。
SuperClaude v3 | #框架
A Survey on LoRA of Large Language Models:大型语言模型参数高效微调利器LoRA综述资源库
• LoRA(低秩适配)通过插入低秩矩阵,实现对大模型密集层的高效微调,显著降低参数量与计算成本。
• 支持跨任务泛化,结合多种LoRA插件提升适应性,兼顾隐私保护,适合联邦学习场景。
• 分类详尽,涵盖下游任务优化、效率提升、过拟合缓解、动态秩分配、梯度压缩、多专家混合等前沿方法。
• 丰富应用覆盖语言理解、代码生成、模型对齐、医学、金融、视觉、音视频多模态等多个垂类领域。
• 配套大量最新论文与开源代码,持续更新,助力研究者和工程师深入掌握LoRA技术全貌与未来趋势。
• 方法论提炼强调:参数效率 ≠ 简单减参,需结合动态分配、优化策略及混合专家机制实现泛化与稳健性。
• LoRA(低秩适配)通过插入低秩矩阵,实现对大模型密集层的高效微调,显著降低参数量与计算成本。
• 支持跨任务泛化,结合多种LoRA插件提升适应性,兼顾隐私保护,适合联邦学习场景。
• 分类详尽,涵盖下游任务优化、效率提升、过拟合缓解、动态秩分配、梯度压缩、多专家混合等前沿方法。
• 丰富应用覆盖语言理解、代码生成、模型对齐、医学、金融、视觉、音视频多模态等多个垂类领域。
• 配套大量最新论文与开源代码,持续更新,助力研究者和工程师深入掌握LoRA技术全貌与未来趋势。
• 方法论提炼强调:参数效率 ≠ 简单减参,需结合动态分配、优化策略及混合专家机制实现泛化与稳健性。
Colette:面向技术文档的本地多模态检索增强生成(RAG)开源平台
• 核心采用视觉RAG(V-RAG)技术,将文档转为图像处理,完整保留图表、布局等视觉元素,提升对复杂技术文档的理解能力
• 支持文本RAG,结合非结构化文本抽取、嵌入和主流大语言模型,实现多模态融合检索与交互
• 多模型支持,兼容多种嵌入器与视觉语言模型,灵活适配不同场景
• 集成图像生成(diffusers),增强交互体验与内容创作能力
• 自托管部署,基于Docker,满足数据隐私需求,适合存储和处理敏感技术资料
• 适用环境配置明确(GPU≥24GB,内存≥16GB,磁盘≥50GB),确保性能稳定
• 详细命令行与Python API示例,方便快速集成与二次开发
• 困难排查指南助力优化检索准确性,支持社区反馈与持续迭代
从本质看,Colette围绕“视觉优先”的多模态理解方法,突破传统文本检索局限,提升技术文档智能交互的深度和精度,适合企业与研发机构构建安全、可控的知识管理系统。
#资源参考 #RAG
• 核心采用视觉RAG(V-RAG)技术,将文档转为图像处理,完整保留图表、布局等视觉元素,提升对复杂技术文档的理解能力
• 支持文本RAG,结合非结构化文本抽取、嵌入和主流大语言模型,实现多模态融合检索与交互
• 多模型支持,兼容多种嵌入器与视觉语言模型,灵活适配不同场景
• 集成图像生成(diffusers),增强交互体验与内容创作能力
• 自托管部署,基于Docker,满足数据隐私需求,适合存储和处理敏感技术资料
• 适用环境配置明确(GPU≥24GB,内存≥16GB,磁盘≥50GB),确保性能稳定
• 详细命令行与Python API示例,方便快速集成与二次开发
• 困难排查指南助力优化检索准确性,支持社区反馈与持续迭代
从本质看,Colette围绕“视觉优先”的多模态理解方法,突破传统文本检索局限,提升技术文档智能交互的深度和精度,适合企业与研发机构构建安全、可控的知识管理系统。
#资源参考 #RAG